EKS service with internal NLB, but gets timeouts randomly
While deploying both client and server on the EKS cluster and connecting through internal NLB, however, the communication gets timeout randomly.

Summary
While deploying both client and server on their EKS cluster and connecting through internal NLB, however, the communication gets timeout randomly.
Problem
In Kubernetes, we can expose the pod to cluster with Kubernetes Service. For sure, we can create a Kubernetes Service of type LoadBalancer, AWS NLB, or CLB is provisioned that load balances network traffic.

Figure source: https://www.docker.com/blog/designing-your-first-application-kubernetes-communication-services-part3/
To manage the workload easily, we might want to deploy both the client and server sides on Kubernetes. However, in the following conditions, you might notice the timeout issue happen randomly.
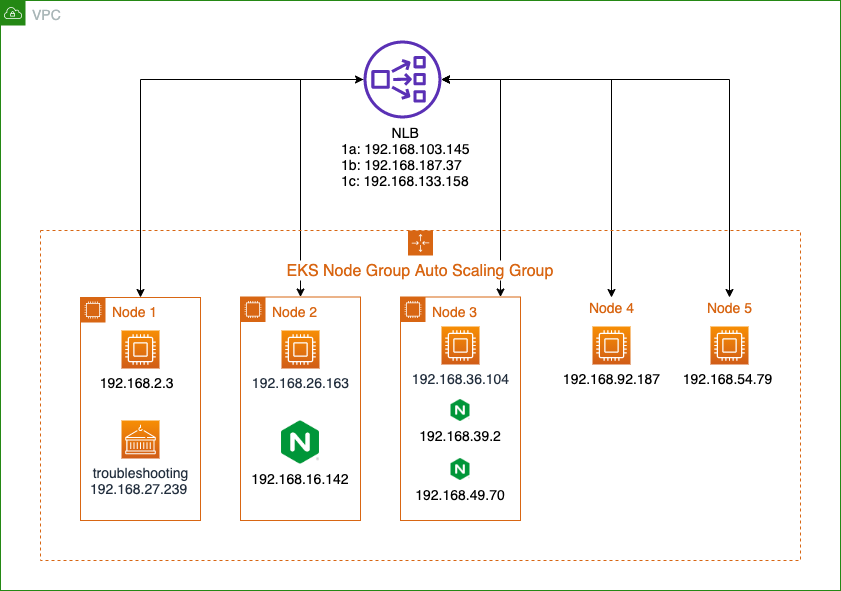
This use case includes both server-side and client-side in the same EKS cluster, and the server-side must use Kubernetes service with internal NLB - instance target type.
- Create a Kubernetes Deployment as server-side. For example, self-host Redis, Nginx server, etc.
- Create a Kubernetes Service to expose the server application through the internal NLB.
- Create another Kubernetes Deployment to test the application as client-side, and try to connect with the server's service.
Reproduce
In my testing, I launched the Kubernetes cluster with Amazon EKS (1.8.9) with default deployments (such as CoreDNS, AWS CNI Plugin, and kube-proxy). The issue can be reproduced as the steps below:
-
Deploy a Nginx Deployment and a troubleshooting container. I used the netshoot as troubleshooting pod, which had preinstalled the
curlcommand. Also, you can find thenginx-nlb-service.yamlandnetshoot.yamlin the attachments.$ kubectl apply -f ./netshoot.yaml $ kubectl apply -f ./nginx-nlb-service.yaml
-
Use the
kubctl execcommand to attach into troubleshooting(netshoot) container.$ kubectl exec -it netshoot -- bash bash-5.1# -
Access the internal NLB domain name(Nginx's Service) via
curlcommand, the connection will timeout randomly. At the same time, I capture the packets through withtcpdumpcommand in EKS worker node.# In the EKS worker node(192.168.2.3) $ sudo tcpdump -i any -w packets.pcap bash-5.1# date Mon Mar 22 23:35:13 UTC 2021 bash-5.1# curl a7487a27201f2434490bada8096adce3-221f6e1d21fadd5b.elb.eu-west-1.amazonaws.com ... It will timeout randomly, you might need to try more times. ... $ date Mon Mar 22 23:35:32 UTC 2021
Why do we get the timeout from the Internal NLB
Firstly, we must know the NLB introduced the source IP address preservation feature[3]: the original IP addresses and source ports for the incoming connections remain unmodified. When the backend answers a request, the VPC internals capture this packet and forward it to the NLB, which will forward it to its destination.
Therefore, if the worker node is running the client-side, and NLB forward to the same nodes. It will generate a random connection timeout. We can dive into this process:
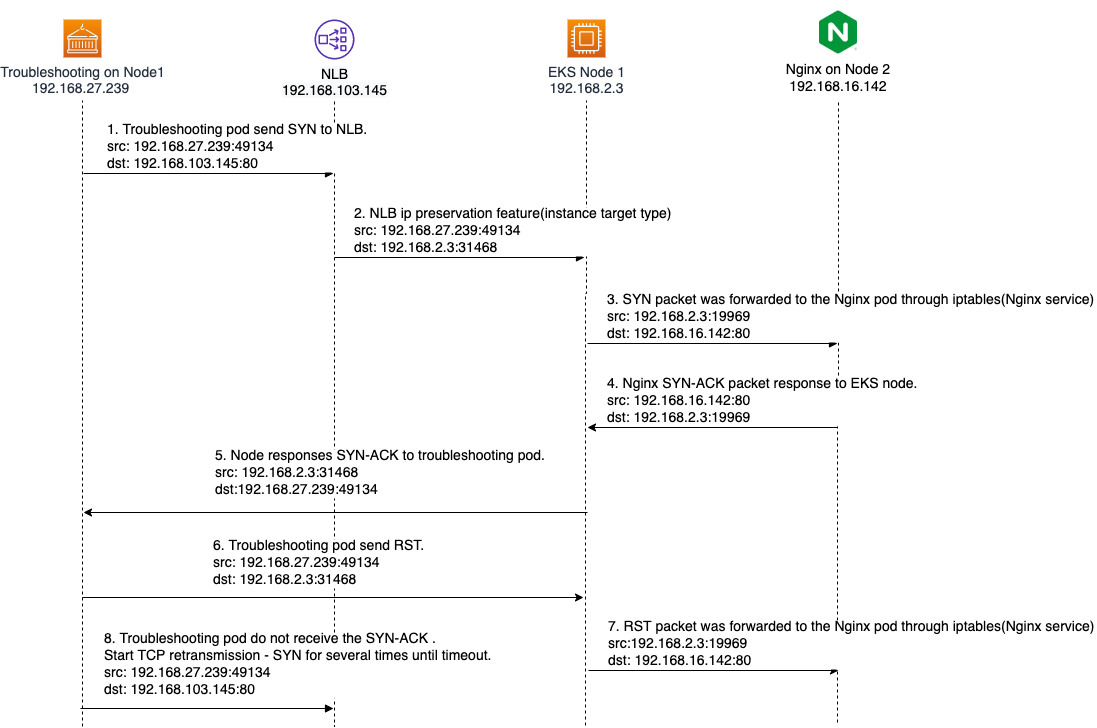
-
The troubleshooting container starts from an ephemeral port and sends a SYN packet.
- src: 192.168.27.239:49134
- dst: 192.168.168.103:80
-
The NLB receives the SYN packet and forwards it to the backend EKS worker node 192.168.2.3 with target port 31468, which was registered by Kubernetes Service. NLB modified the destination IP address as Client IP preservation feature. Thus, the EKS worker node receives a SYN packet:
- src: 192.168.27.239:49134
- dst: 192.168.2.3:31468
-
Base on the iptables rules(Nginx Service) on the EKS worker node, this SYN packet was forwarded to the Nginx pod.
- src: 192.168.2.3:19969
- dst: 192.168.16.142:80
# Kubernetes Service will update the following iptables rules in every node. $ sudo iptables-save | grep "service-nginx-demo" -A KUBE-NODEPORTS -p tcp -m comment --comment "nginx-demo/service-nginx-demo:" -m tcp --dport 31919 -j KUBE-MARK-MASQ -A KUBE-NODEPORTS -p tcp -m comment --comment "nginx-demo/service-nginx-demo:" -m tcp --dport 31919 -j KUBE-SVC-7D7VEXWNCKBQRZ7W -A KUBE-SEP-2IF7DICDPRGPK5UI -s 192.168.39.2/32 -m comment --comment "nginx-demo/service-nginx-demo:" -j KUBE-MARK-MASQ -A KUBE-SEP-2IF7DICDPRGPK5UI -p tcp -m comment --comment "nginx-demo/service-nginx-demo:" -m tcp -j DNAT --to-destination 192.168.39.2:80 -A KUBE-SEP-2V4THTSJVFKRX4LC -s 192.168.16.142/32 -m comment --comment "nginx-demo/service-nginx-demo:" -j KUBE-MARK-MASQ -A KUBE-SEP-2V4THTSJVFKRX4LC -p tcp -m comment --comment "nginx-demo/service-nginx-demo:" -m tcp -j DNAT --to-destination 192.168.16.142:80 -A KUBE-SEP-73EDW25F4C3YFWYZ -s 192.168.49.70/32 -m comment --comment "nginx-demo/service-nginx-demo:" -j KUBE-MARK-MASQ -A KUBE-SEP-73EDW25F4C3YFWYZ -p tcp -m comment --comment "nginx-demo/service-nginx-demo:" -m tcp -j DNAT --to-destination 192.168.49.70:80 -A KUBE-SERVICES -d 10.100.235.20/32 -p tcp -m comment --comment "nginx-demo/service-nginx-demo: cluster IP" -m tcp --dport 80 -j KUBE-SVC-7D7VEXWNCKBQRZ7W -A KUBE-SVC-7D7VEXWNCKBQRZ7W -m comment --comment "nginx-demo/service-nginx-demo:" -m statistic --mode random --probability 0.33333333349 -j KUBE-SEP-2IF7DICDPRGPK5UI -A KUBE-SVC-7D7VEXWNCKBQRZ7W -m comment --comment "nginx-demo/service-nginx-demo:" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-73EDW25F4C3YFWYZ -A KUBE-SVC-7D7VEXWNCKBQRZ7W -m comment --comment "nginx-demo/service-nginx-demo:" -j KUBE-SEP-2V4THTSJVFKRX4LC
-
Nginx pod replies the SYN-ACK packet back to the EKS worker node. We can view the
tcp.stream eq 9for step 3 and step4.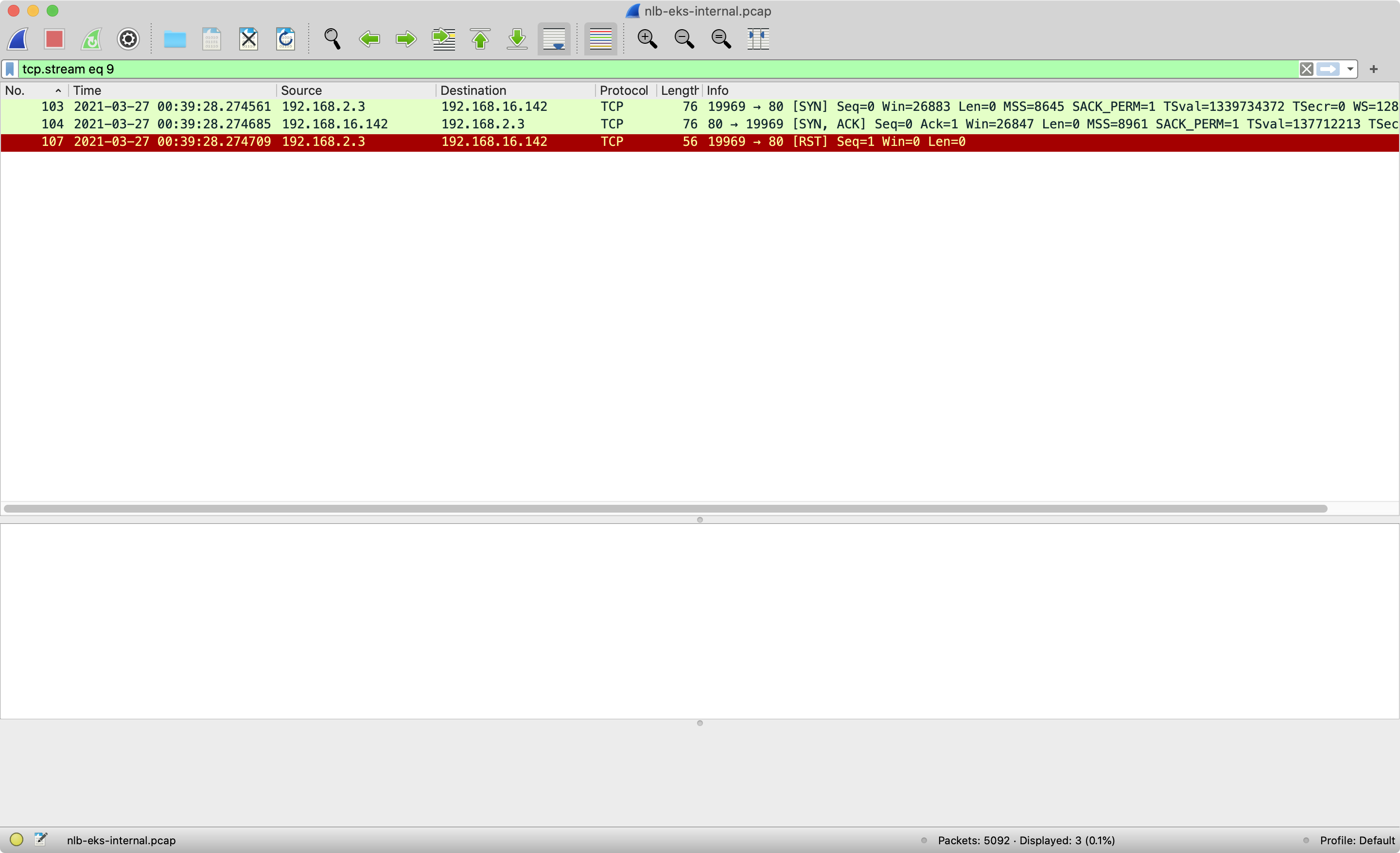
-
VPC CNI plugin maintains the route table for binding the ENI with pod. Base on the route table in Node 1, it will reply the SYN-ACK packet for the SYN packet for troubleshooting pod in step 2.
# Node 1 - routing table $ route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 192.168.32.1 0.0.0.0 UG 0 0 0 eth0 169.254.169.254 0.0.0.0 255.255.255.255 UH 0 0 0 eth0 192.168.32.0 0.0.0.0 255.255.224.0 U 0 0 0 eth0 192.168.27.239 0.0.0.0 255.255.255.255 UH 0 0 0 eni708fb089496 ... -
The troubleshooting pod notices this SYN-ACK connection is an abnormal connection, and send RST packet to close the connection to
192.168.2.3:31468. -
The RST packet is forwarded to the Nginx pod through iptables rules(Nginx server) as well. Also, the troubleshooting container will send both TCP_RETRANSMISSION and RST several times until it times out.
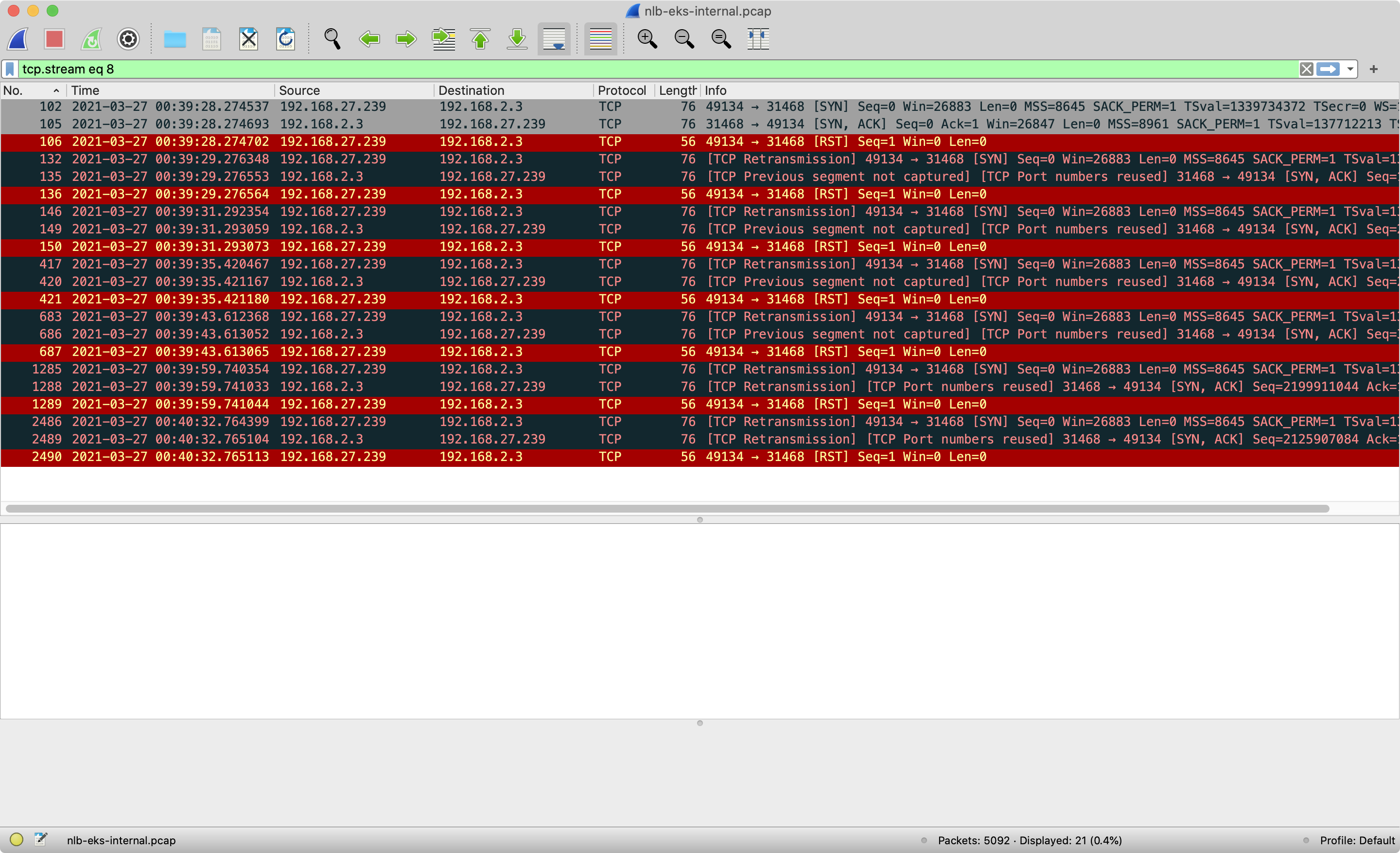
-
The initiating socket(src: 192.168.27.239:49134, dst: 192.168.168.103:80) still expects the SYN-ACK from the NLB 192.168.168.103:80. However, the troubleshooting pod did not receive the SYN-ACK, so the troubleshooting pod will send several TCP RETRANSMISSION - SYN until it times out.
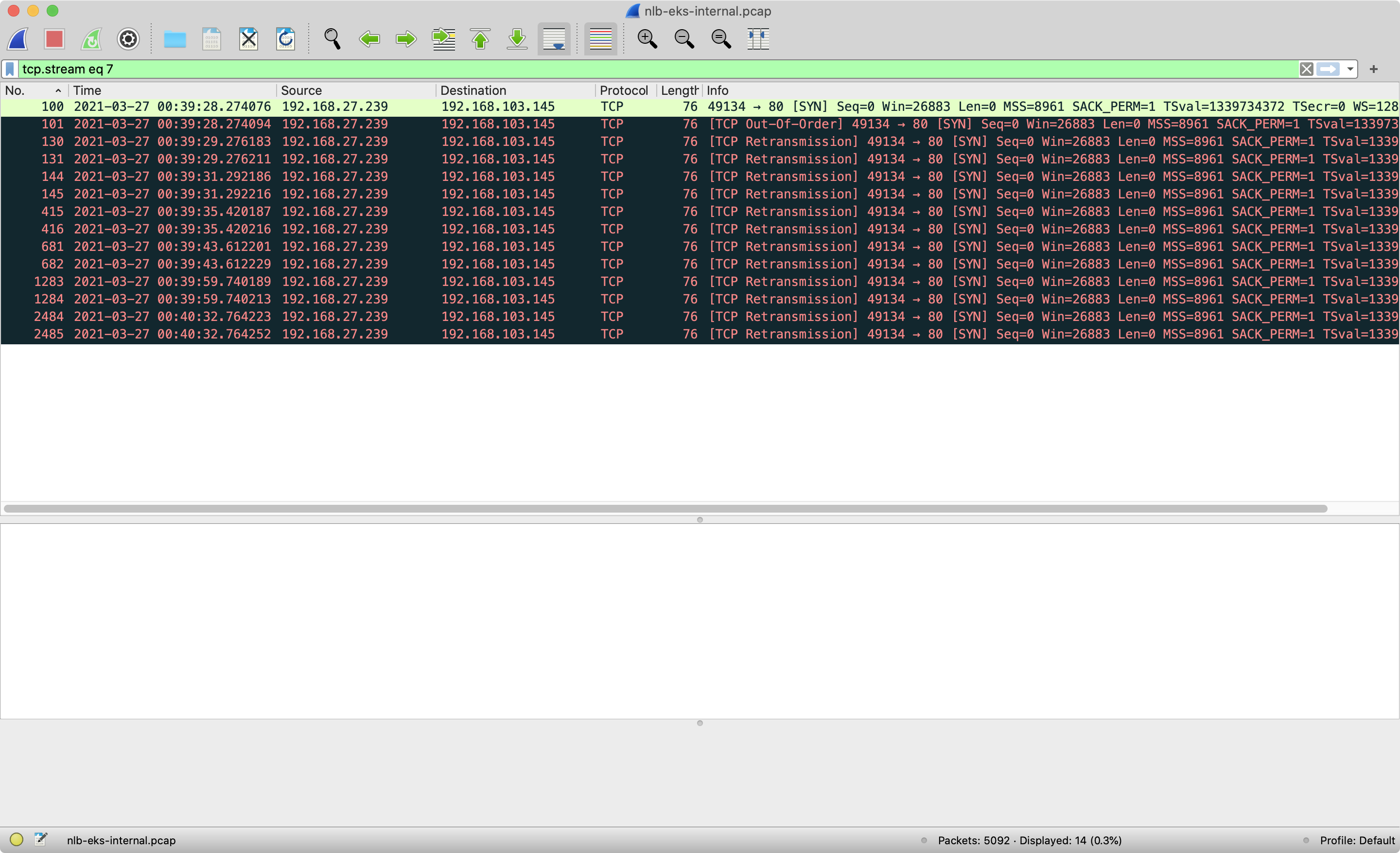
Workaround
If you don't care about keeping the source IP address, we can suggest that you can consider using the NLB IP mode[4].
metadata:
name: my-service
annotations:
service.beta.kubernetes.io/aws-load-balancer-type: "nlb-ip"
2021-05-21 Update
The NLB adds support to configure client IP preservation[5] with instance mode, which is supported in version v2.2.0[6]. Thus, we can use the following annotations for the client IP preservation with instance mode.
- Note: Please use the annotation
service.beta.kubernetes.io/aws-load-balancer-type: "external"to ignore in-treecloud-controller-manager[7] to create an in-tree NLB service.
...
annotations:
service.beta.kubernetes.io/aws-load-balancer-type: "external"
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: instance
service.beta.kubernetes.io/aws-load-balancer-target-group-attributes: "preserve_client_ip.enabled=false"
...
References
- Connecting Applications with Services - https://kubernetes.io/docs/concepts/services-networking/connect-applications-service/
- Network load balancing on Amazon EKS - https://docs.aws.amazon.com/eks/latest/userguide/load-balancing.html
- Target groups for your Network Load Balancers - Client IP preservationhttps://docs.aws.amazon.com/elasticloadbalancing/latest/network/load-balancer-target-groups.html#client-ip-preservation
- https://kubernetes-sigs.github.io/aws-load-balancer-controller/latest/guide/service/nlb_ip_mode/#nlb-ip-mode
- https://docs.aws.amazon.com/elasticloadbalancing/latest/network/load-balancer-target-groups.html#client-ip-preservation
- AWS Load Balancer Controller - v2.2.0 - https://github.com/kubernetes-sigs/aws-load-balancer-controller/releases/tag/v2.2.0
- AWS Load Balancer Controller - Network Load Balancer - https://kubernetes-sigs.github.io/aws-load-balancer-controller/v2.2/guide/service/nlb/#configuration